《DAY 1》
🚀 快速掌握本文精華
- 生成式 AI 不只「分析」,更能 無中生有
- GAN:對抗式訓練,擅長高擬真影像
- Diffusion:逐步去噪,擅長多樣與創意的「文生圖」
- 代表工具與案例:StyleGAN、This Person Does Not Exist、Midjourney、DALL·E 2
- 下一步(Day 2):大型語言模型(LLM)如何理解語意與推理
過去,我們對 AI 的印象多半停留在資料分析、模式識別與預測。
近年來,生成式 AI(Generative AI) 迅速崛起:從逼真的人臉影像到充滿風格的插畫、音樂與文本,都能透過模型「創造」出來。
一場「偽造者」與「鑑賞家」的對決
訓練流程(對抗學習)
代表應用
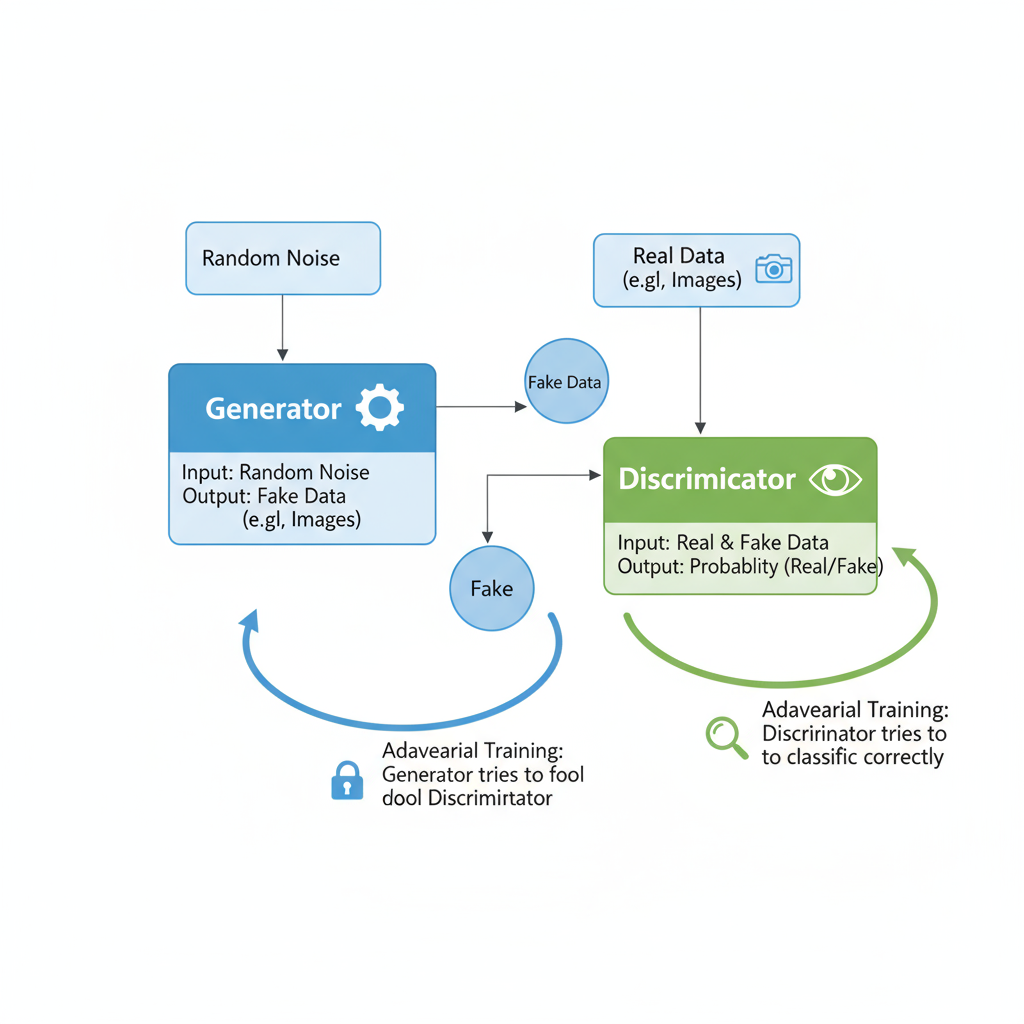
圖 1:GAN 的生成器與判別器互相對抗、共同進化
✨ 小結:GAN 擅長「寫實」,但訓練可能不穩、易出現模式崩塌(多樣性不足)。
從混沌到清晰的「還原」藝術
為何適合文生圖?

圖 2:Diffusion 由 Noise 經反向去噪生成清晰影像
✨ 小結:Diffusion 具 品質穩定+多樣化 的優勢,尤其擅長文字驅動的創作。
| 模型 | 優勢 | 限制 | 代表應用 |
|---|---|---|---|
| GAN | 高度寫實、細節逼真 | 訓練不穩定、模式崩塌 | StyleGAN、BigGAN |
| Diffusion | 多樣性高、訓練較穩定、擅長文生圖 | 生成步驟多、速度較慢 | Stable Diffusion、DALL·E 2、Midjourney |

圖 3:GAN 偏擬真、Diffusion 偏創意與風格多變
選型建議(實務)
從 GAN 的對抗學習 到 Diffusion 的逐步還原,生成式 AI 已成為內容創作與設計的 核心引擎。
它不只是演算法,更像具有「想像力」的數位合作者,能把你的靈感變成具體作品。
🔜 Day 2 預告:大型語言模型(LLM)如何理解語意、與人對話,乃至展現推理力?
#生成式AI #GAN #Diffusion模型 #AI繪圖 #StableDiffusion #Midjourney #DALLE2 #AI創作 #人工智慧 #深度學習
感謝版主分享!這篇文章對於生成式 AI 的核心概念,特別是 GAN 與 Diffusion 模型,講解得非常清晰易懂。
TL;DR 的精華總結和對照表很棒,讓讀者能快速掌握重點。我很喜歡您將 GAN 形容為「偽造者」與「鑑賞家」的對決,以及 Diffusion 的「從混沌到清晰」的還原藝術,這些比喻都讓複雜的技術變得生動許多。尤其最後的選型建議,對於實際應用情境的考量很有參考價值。
已經開始期待 Day 2 關於大型語言模型(LLM)的分享了!
也歡迎版主有空參考我的系列文「南桃AI重生記」:
https://ithelp.ithome.com.tw/users/20046160/ironman/8311

